
News
Blind Users Accessing Their Training Images in Teachable Object Recognizers (Summary)
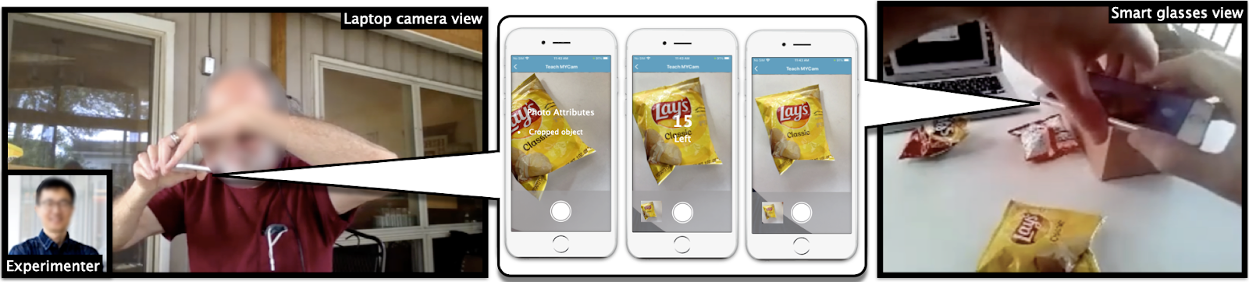
Teachable object recognizers allow blind users to train their camera-equipped devices such as mobile phones to recognize everyday objects by providing a few photos as training examples. A user takes a series of pictures of an object to “train” the machine learning model how to distinguish that object from other objects, so that in the future, when the user uses the recognizer, it can identify the object. Thus, the blind user can take the right medicine, select the wanted drink or snack, or identify the appropriate key.
While computer vision included in smartphones or smartglasses has long been considered as a potential benefit for people with disabilities, in order to teach the machine learning model to recognize objects on their behalf, a user must aim a camera and review the training images —tasks that require similar abilities to those the technology is aiming to augment. Therefore it is critical that means of interacting with the machine learning model afford blind users access to their training examples so that they can effectively improve the model. Such interactions will also allow blind users to gain more familiarity with artificial intelligence and therefore contribute to the larger goal of making the process of teaching machines easy, fast, and universally accessible.
To improve access for blind users to the training of teachable object recognizers, researchers from the University of Maryland’s iSchool conducted a study to explore the potential of using ‘data descriptors’ as a form of non-visual access to training data. The results of this study are reported in “Blind Users Accessing Their Training Images in Teachable Object Recognizers,” a paper by former and current students at UMD, Jonggi Hong, Jaina Gandhi, Ernest Essuah Mensah, Farnaz Zamiri Zeraati, Ebrima Haddy Jarjue, Kyungjun Lee, and Dr. Hernisa Kacorri (core faculty and principal investigator at the Trace R&D Center). This paper, a Best Paper Nominee at ASSETS ’22, will be presented at the 24th International ACM SIGACCESS Conference on Computers and Accessibility in Athens, Greece, on October 24, 2022.
This remote user study involved 12 blind participants in their homes who employed MYCam, an open-source, screen-reader accessible, iOS mobile app that serves as a testbed for deploying descriptors in a teachable object recognizer. The participants were all regular users of smartphones which they reported using for taking photos/videos at least once a month (though many reported experiencing challenges with taking photos). Participants had varying degrees of familiarity with machine learning though no one was an expert. Many had prior experience with other camera-based assistive mobile applications (e.g., Seeing AI, Be My Eyes). Researchers were able to observe the users via Zoom though both a laptop view and a smartglasses view.
(A paper describing the study design and the implications of this work for the field, From the Lab to People’s Home: Lessons from Accessing Blind Participants’ Interactions via Smart Glasses in Remote Studies, was published in the proceedings of the 19th International Web for All Conference (Web4All 2022) and summarized in this Trace Center news story.)
The MYCam app and its purpose was explained to the study participants like this:
The idea behind the app is that you can teach it to recognize objects by giving it a few photos of them, their names, and if you wish, audio descriptions. Once you’ve trained the app and it has them in its memory, you can point it to an object, take a photo, and it will tell you what it is. You can always go back and manage its memory.
Participants were given three tasks: (1) Train the app with their own photos and labels of three snacks (Fritos, Cheetos, and Lays potato chips). The study used three objects of similar size, texture, and weight so that it would be similar to the challenging types of visual discrimination most useful in real-life use. They took 30 photos of each snack and labeled the photos with the name of the object in a text field or using an audio description. (2) Use the app to recognize the objects later to test the performance of the app. (3) Review and edit information of the already trained objects.
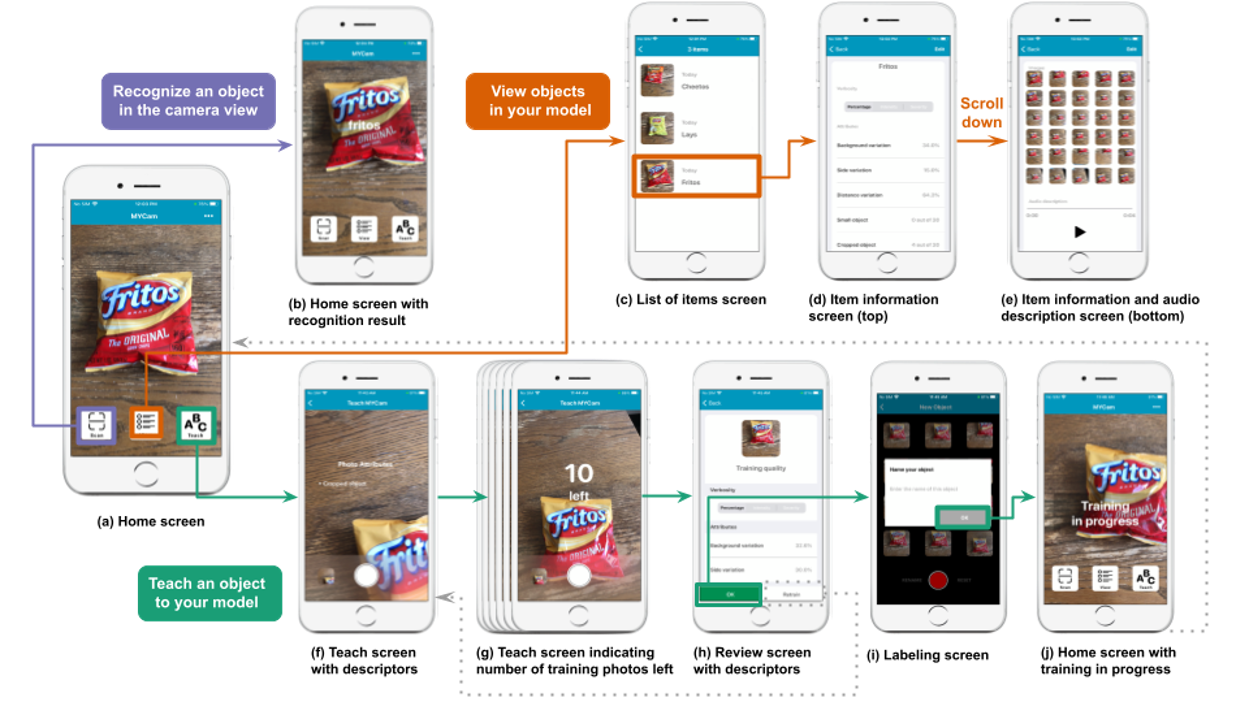
Rather than having a person manually code the relevant attributes of each photo through visual inspection, MYCam, using state-of-the art computer vision techniques, attempts to automatically provide descriptions of the training data at both the photo- and the set-level. Photo-level descriptors communicate real-time information to the user about the following attributes of each photo: blurriness, presence of their hand, object visibility, and framing. Set-level descriptors communicate information one would get from glancing over a whole group of training photos—e.g., the percentage of variation in background, distance, and perspective across the set of photos of one object. At the end of the training session, users can either accept the training data or retrain the model with new photos.
After reviewing the initial training sets, five of the 12 participants chose to retrain the model for at least one of the objects with a new set of photos. These new training sets had fewer photos with cropped objects, no hands included, almost no blurred photos, and higher variation in perspective and size on average compared to their initial photos. Even without retraining, the photo-level descriptors allowed participants to make adjustments as they progressed in the study—with fewer images where the object was cropped over time, both within a set of images for one object and over the three sets of photos for all three objects (where participants also had set-level descriptors they could consider when training the next object). In other words, the descriptors helped the users to become better at training the models in real time while performing the study tasks.
Participants used a very small number of photos to check if their models were working. The average accuracy, i.e., how often a new photo of an object was correctly recognized based on the model, was 0.65 (with a standard deviation of 0.24). Model performance was better against a given individual participant’s test set than it was against an aggregated test set of all participants and testing photos from a prior study. An additional finding was that two of the five participants who retrained their models with a new set of photos of at least one object ended up with models that had higher accuracy.
The study also gathered feedback from the participants after completing the study tasks. Participants agreed that they could train the object recognition effectively using MYCam and did not feel that the training was difficult. They were divided on whether the training could be done quickly. Almost all participants agreed that the descriptors were easy to understand and useful, but most thought it would have been helpful to include more explicit guidance on how to improve the training photos (e.g., “move the camera slightly to the right”). Overall, the study participants’ satisfaction with the performance of the object recognizer was tied to both the accuracy of the model and the effort they expended to do the training.
In sum, this study provides evidence that descriptors derived from visual attributes used to code training photos in teachable object recognizers can provide blind users with a means to inspect their data, iterate, and improve their training examples. Challenges that remain involve onboarding of participants, the time needed for training, as well as descriptor accuracy and interpretation. The approach employed here is valuable also because it could also be used for other teachable applications – and perhaps inform more accessible approaches to AI interfaces by addressing the problem of assistive applications where training requires similar skills to those the technology aims to fulfill (e.g., teachable object recognizers for the blind, teachable sound detectors for Deaf/deaf and HOH people).
Going forward, Dr. Kacorri’s team is excited to continue their endeavors towards building more inclusive participatory machine learning experiences both for blind youth and adults.
This work is supported by the National Science Foundation (#1816380). Kyungjun Lee is supported by the Inclusive Information and Communications Technology RERC (#90REGE0008) from the National Institute on Disability, Independent Living, and Rehabilitation Research (NIDILRR), Administration for Community Living (ACL), Department of Health and Human Services (HHS).
Hong, J., Gandhi, J., Mensah, E. E., Zeraati, F. Z., Jarjue, E. H., Lee, K., & Kacorri, H. (2022). Blind users accessing their training images in teachable object recognizers. ASSETS ‘ 22: The 24th International ACM SIGACCESS Conference on Computers and Accessibility.New York: ACM. https://dl.acm.org/doi/10.1145/3517428.3544824